0.Intro
Line Developers 에서 발표한 MLOps 의 주요한 요소인, 모니터링 시스템에 관한 내용.
유튜브 원본 영상: Lupus-MLOps 가속화를 위한 모니터링 시스템 - 2021 korean version -
1. MLOps and MLOps Monitoring
1-1. MLOps 란,
ML Product 개발에서의 DevOps 를 말한다. 기존의 DevOps 의 틀로는 커버할 수 없는 영역들이 있기에 생긴 개념.
1-2. MLOps 특징,

ML stage
기계학습 모델을 설계하고, 실험을 통해 성능을 평가하고, 필요한 요건을 충족시키는 로직을 개발한다.
- ML Engineer, Data Scientist, Annotator 들과 협업이 필요함.
Dev stage
어떻게 자원을 확보하고, 어디서 학습시킬 것인지, 그리고 어떻게 빌드해서 배포할 것인지.
Ops stage
운영시에 모델의 정확도 Drift 발생하는 것을 트리거로 하여 재학습을 촉구하는 것이 필요하다.
1-3. 왜 모니터링?
MLOps 에서는 데이터나 모델 등, 코드로는 관리되지 않는 불확실한 요소들이 포함되어 있다. 그리고 이것들은 시간이 지나면서 변할 수 있는 요소들이다. 그래서 MLOps 의 모니터링에서는 일반 Dev 에선 볼 수 없는 특징들이 있다.
1-4. 어떤것을 모니터링?
DevOps
시스템 가동 정보를 중심으로 모니터링 한다.
클라우드 기반으로 어느정도 자동화된 metrics 수집이 가능하다.
높은 빈도로 metrics 수집한다.
- Resource usage (CPU, Memory, Storage... )
- Disk I/O
- Network Traffic
- Heartbeats
- Business KPIs
- etc...
MLOps
시스템 가동 정보 중심 + 모델과 데이터에 관한 정보들을 모니터링 한다.
서비스 환경에 크게 의존하기 때문에 수집이 어렵다.
많은 데이터와 비용이 들기 때문에 수집 하는데에 오랜 시간이 걸린다. (높은 빈도 X)
- Data statistics
- Input data changes (data drift)
- Input - target pattern changes (concept drift)
- Model Performance
- Prediction accuracy
- Diversity of recommendations (task 중점 모니터링 - 추천 시스템)
- Fairness
2. Line MLOps Environment
2-1. Scale


2-2. Facilities
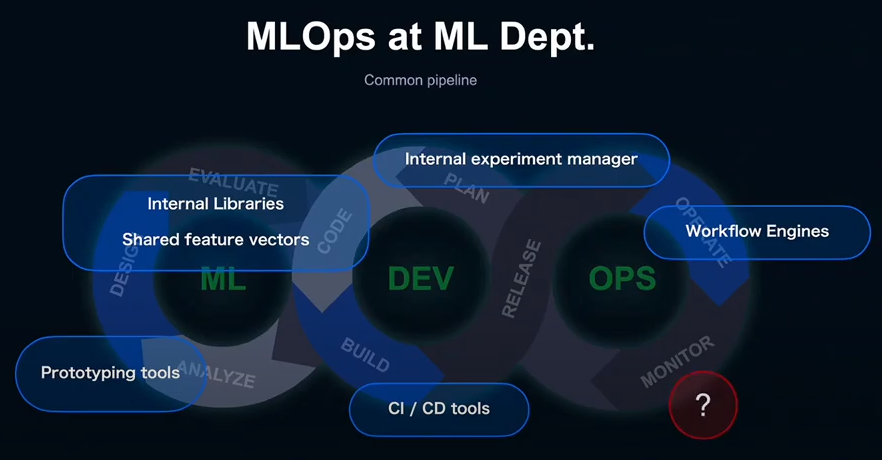
Infrastructure
- Kubernetes
- IU (LINE's Hadoop cluster)
Prototyping environment
- Jutopia (LINE's Jupyter server)
Workflow engines
- Argo Workflows
- Azkaban
- Airflow
CI/CD
- Argo CD
- Drone CI
Shared feature vectors
- User sparse/dense features
- Item metadata features
Internal libraries...
Internal experiment manager...
3. Problems ( challenges ) what LINE's ML team had faced
Increasing monitoring costs
As the number of ML, products increases, the cost of monitoring has steadily grown.
- LINE 에서는 100여개가 넘는 ML 프로덕트를 운영하고 있다.
Disjointed, projet-dependent monitoring operations
각 ML 프로젝트에서 독자적으로 모니터링.
- 모니터링과 Alert 가 각 프로젝트별로 독립적으로 이루어져
- 범위가 최소화
- Alert 만 보여주고 메트릭스 저장 안 함
- 프로젝트에 대한 의존성이 높다
Outages due to lack of monitoring
- 데이터의 결손, 모델의 변화 등, 많은 risk
- 각 프로덕트들, 기능들에 대한 완벽한 모니터링 환경을 구축하는 것은 어렵다.

- Data Missing
- 데이터를 읽을 때, 데이터의 일부가 결손되는 상황이 생기기도 한다.
- ML Product 의 정확한 인풋과 아웃풋을 제대로 모니터링하지 않으면 예측 결과에 이변이 발생해도 빠르게 알기 어렵다.
- 큰 장애가 될 수 있다. -> 빠르게 이 원인을 알아차리기 어렵다.
- Model Update
- LINE) 예측지 분포에 큰 변화가 있음을 알아차리지 못한 경우,
- 정확도가 오르더라도 분포가 크게 바뀐다면, 추천 시스템의 경우, 사용자의 속성이 변하면서 추천 시스템이 올바르게 작동하지 않았다.
- LINE) 예측을 안정화 시키기 위해 과거모델의 예측지와 다수결로 처리하는 후처리를 했다.
- 문제 발견까지 보름정도 시간이 걸렸다.
- 복구에 큰 비용이 들었다.
- LINE) 예측지 분포에 큰 변화가 있음을 알아차리지 못한 경우,
- 한 프로젝트에서 자체적인 모니터링 시스템을 구축했을 경우,
- 수집하는 메트릭스가 당시에만 필요했던 것으로 한정되어 있거나
- alert 조건이 간소한 조건으로 한정되어 있었다.
- 코드리뷰 부족으로 신회성 부족.
4. Possible Solutions what LINE ML Team considered

메트릭스 수집을 가능한 효율적으로 수집할 수 있게끔 환경 구축.
- 메트릭스를 집계할 수 있는 툴셋
- 메트릭스 저장소
- 유연한 에러 디텍터
- 알림 시스템
- 수집한 메트릭스를 쉽게 볼 수 있는 가시화 시스템
5. Lupus: MLOPs 를 위한 모니터링 앱
5-1. Concepts

- 엔지니어가 쉽게 메트릭스를 수집한다
- 운영자가 쉽게 에러를 탐지할 수 있다
- 프로젝트 멤버 모두가 쉽게 메트릭스와 각종 이상을 가시화 할 수 있어야 한다
5-2. Components

- Lupus Server
- Metrics management and anomaly detection APIs
- Lupus library
- Metrics aggregation tools and API client
- Lupus SPA
- Web app for metrics and anomalies visualization
5-3. 각 기능 / Usecase 설명
Metrics Collection (Aggregation library 내용)
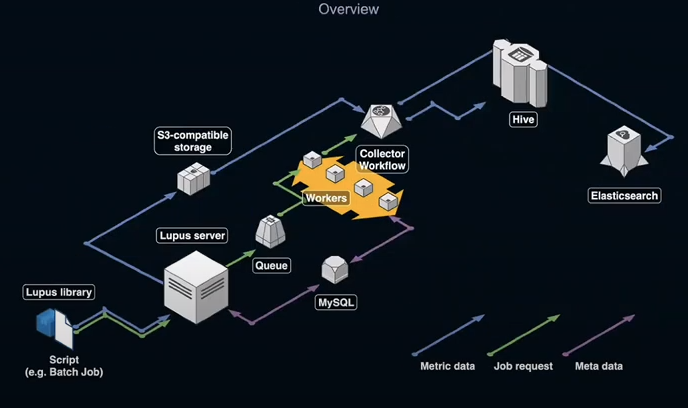
- Data drift / Concept drift
- 인풋데이터와 타겟 변수들의 통계량 수집
- 모델의 퍼포먼스 감시
- 평가지표의 계산하는 라이브러리
- 프로젝트간, 로직간 지표 비교할 때 쉬워짐. -> 같은 방법으로 계산.
- ML flow 에 기록된 Metrics 를 가져오는 기능
- 예) 테이블 형식의 데이터의 경우,
- PySpark 를 이용하여 분산처리
- 특정 키워드, 혹은 조건 (Region 이라던지,) 를 기준으로 통계량 추출해야 할 때, 코드가 매우 길어짐.
- Aggregation Library 를 통해 작성.

Anomaly Detection (이상 탐지)

- Basic
- 임계치가 넘으면 알림이 뜨는 기능
- 가장 최근의 값과 비교했을 때 변화가 클 때 알림이 뜨는 기능
- ML
- 주기적인 변화에서 크게 이탈했을 때 알림이 뜨는 기능
- 트렌드가 변화했을 때 알림이 뜨는 기능
- Lupus에서 사용되는 이상 감지 ML 로직들
- Thresholding
- Window-based Rules
- 가장 최근 값과 비교..
- Time-series prediction by Prophet
- 시계열 예측 -> 과거의 데이터를 통해 시계열 예측, 신뢰구간을 바탕으로 이상여부를 판단
- Twitter's anomaly detection package
Visualization

- 대시보드 커스터마이징 가능
- 키바나 연동 가능
- 메트릭 선택하여 가시화 가능
'ML+DL+Ops > 영상 자료 정리' 카테고리의 다른 글
| MLOps Explained | Machine Learning Essentia (0) | 2022.05.18 |
|---|---|
| [MLOpsKR 커뮤니티 발표 2021] Kubeflow + KRSH vs Airflow (1) | 2022.04.18 |


댓글